
II concetto fondamentale che dobbiamo trattare a questo punto è il protocollo HTTP (HyperText Transfer Protocol), che costituisce il meccanismo di trasferimento alla base del Web e il metodo preferito per scambiare documenti indicizzati da URL tra server e client. Nonostante la presenza del termine hypertext nel nome, il protocollo HTTP e il vero e proprio contenuto ipertestuale (il linguaggio HTML) spesso esistono indipendentemente l’uno dall’altro. Ciò premesso, a volte sono intrecciati anche in modi sorprendenti.
La storia di HTTP offre un’interessante visione sulle ambizioni dell’autore e sulla crescente rilevanza di Internet. La prima bozza del protocollo (HTTP/0.91) datata 1991 è scritta da Tim Berners-Lee, era lunga a malapena una pagina e mezza e mancava anche delle più intuitive funzioni che si sarebbero rese necessarie in futuro, come l’estendibilità richiesta per la trasmissione di dati non HTML.
Cinque anni e diverse iterazioni della specifica dopo, il primo standard ufficiale HTTP/1.0 (RFC 19452) provò a rettificare queste mancanze in circa 50 pagine fitte di testo. Arriviamo al 1999 e con HTTP/1.1 (RFC 26163) i sette autori accreditati tentarono di anticipare quasi ogni possibile utilizzo del protocollo, creando un volume di 150 pagine.
E non è tutto: al momento in cui scriviamo, si lavora su HTTPbis4, sostanzialmente un sostituto di HTTP/1.1, con una specifica di circa 360 pagine. Anche se molto del contenuto accumulato è irrilevante per il Web moderno, questa progressione evidenzia che il desiderio di aggiungere nuove funzioni supera di gran lunga quello di rimuovere le funzioni scarsamente utilizzate.
Oggi tutti i client e server supportano un sovrainsieme non proprio accurato di HTTP/1.0, mentre la maggioranza parla un dialetto ragionevolmente completo di HTTP/1.1, con l’aggiunta di alcune eccezioni. Nonostante non esista alcun motivo pratico per farlo, molti server web e tutti i browser più comuni mantengono la compatibility all’indietro con HTTP/0.9.
Sintassi di base del traffico HTTP
A prima vista HTTP è un semplice protocollo di testo basato su TCP/IP. TCP (Transmission Control Protocol) è uno dei protocolli di comunicazione alla base di Internet. Fornisce il livello di trasporto a tutti i protocolli applicativi basati su di esso.
Offre una connettività ragionevolmente affidabile, ordinata, con mutuo riconoscimento e orientata alle sessioni tra host di rete. Nella maggioranza dei casi tale protocollo si dimostra anche abbastanza resistente rispetto ad attacchi – come il blind packet spoofing – portati da altri host non locali su Internet. Ogni sessione HTTP comincia stabilendo una connessione TCP al server, tipicamente sulla porta 80, quindi effettuando una richiesta contenente un URL. In risposta, il server produce il file richiesto e, nel caso più rudimentale, chiude la connessione TCP immediatamente dopo.
Lo standard HTTP/0.9 originale non prevedeva alcuno spazio per lo scambio di metadati aggiuntivi tra le parti coinvolte. La richiesta del client consisteva sempre di un’unica riga, che iniziava con GET seguito dal percorso e dalla stringa di query dell’URL e terminata con un singolo avanzamento di riga CRLF (codici ASCII OxOD OxOA; per i server era consigliato accettare anche un singolo LF). Una richiesta HTTP/0.9 poteva quindi avere l’aspetto seguente:
GET /-fuzzy_bunnies.txt
In risposta a questo messaggio, il server inviava immediatamente il carico di dati HTML. La specifica richiedeva che i server restituissero righe lunghe esattamente 80 caratteri, ma questo consiglio non e mai stato seguito da nessuno.
L’approccio di HTTP/0.9 presenta diverse lacune sostanziali. Per esempio, non da modo al browser di comunicare le preferenze linguistiche dell’utente, di fornire un elenco di tipologie di documenti supportati, e così via. Inoltre non da modo al server di informare che il file richiesto non e stato trovato, che è stato spostato a un altro indirizzo o che il file scaricato non è un documento HTML – solo per iniziare.
Infine, il protocollo non è gentile con gli amministratori dei server: essendo l’URL limitato a percorso e stringa di query, è impossibile per un server ospitare siti diversi, distinti dai loro nomi di host, con un solo indirizzo IP e – a differenza dei record DNS – gli indirizzi IP non sono economici.
Per sanare queste lacune (e per fare spazio a futuri trucchi), gli standard HTTP/1.0 e HTTP/1.1 implementano un formato di conversazione leggermente differente: alla prima riga della richiesta viene aggiunta la versione del protocollo utilizzato, di seguito potranno esserci zero o più coppie nome: valore (note come header) ciascuna su una riga a sé. Gli header più comuni che si possono trovare nelle richieste sono User-Agent (la versione del browser), Host (il nome dell’host presente nell’URL), Accept (i tipi di documento MIME supportati. II tipo MIME, noto anche come Internet media type, è un semplice valore formato da due componenti che identifica la classe e il formato di ogni tipo di file. IL concetto nasce negli RFC 2045 e RFC 2046, dove serviva a descrivere i vari tipi di allegati della posta elettronica.
L’elenco ufficiale di tali valori, come text/plain o audio/mpeg, è attualmente mantenuto dall’IANA, ma tipi ad hoc sono decisamente comuni), Accept-Language (le lingue accettate) e Referer (un campo – dal nome curiosamente scritto in modo errato per la lingua inglese – che indica la pagina di provenienza della richiesta, se esiste).
Gli header si concludono con un’unica riga vuota, la quale può essere seguita da qualsiasi dato il client voglia passare al server (la cui lunghezza in byte dev’essere specificata esplicitamente con l’header Content-Length).
Il contenuto di questo carico di dati e opaco per il protocollo; in HTML questo spazio viene generalmente utilizzato per l’invio dei dati dei moduli in uno dei diversi formati possibili, anche se non è in alcun modo vincolante.
Quindi, una richiesta HTTP/1.1 può avere l’aspetto seguente:
POST /fuzzy_bunnies/bunny_dispenser.php HTTP/1.1 Host: www.fuzzybunnies.com User-Agent: Bunny-Browser/1.7 Content-Type: text/plain Content-Length: 17 Referer: http://www.fuzzybunnies.com/main.html I REQUEST A BUNNY
Il server deve rispondere a questa richiesta con una riga nella quale dichiara la versione di protocollo supportata, un codice di stato numerico (utilizzato per indicare condizioni di errore e altre circostanze particolari) e, opzionalmente, un messaggio di stato in formato leggibile dall’uomo. Quindi seguono diversi header auto-esplicativi che terminano con una riga vuota. La risposta prosegue con il contenuto della risorsa richiesta:
HTTP/1.1 200 OK Server: Bunny-Server/O.9.2 Content-Type: text/plain Connection: close BUNNY WISH HAS BEEN GRANTED
Comportamento dell’header Referer
Come abbiamo anticipato precedentemente in questo capitolo, le richieste HTTP possono contenere un header Referer che contiene l’URL del documento da cui in qualche modo proviene la navigazione. Esso è destinato a favorire la ricerca di errori di programmazione e a promuovere la crescita del Web enfatizzando i riferimenti incrociati tra le pagine web.
Sfortunatamente, questo header può rivelare anche alcune informazioni sulle abitudini di navigazione dell’utente a dei malintenzionati, e lasciar scappare informazioni sensibili codificate nei parametri della stringa di query della pagina di provenienza. A causa di queste preoccupazioni e della mancanza di consigli validi su come mitigarne gli effetti, questo header viene spesso abusato per scopi di sicurezza, ma non è adatto a questo compito. II principale problema è che non c’è modo di distinguere un client che non trasmette questo header a causa delle preferenze di privacy dell’utente, da quello che non lo trasmette per il tipo di navigazione in corso, e da quello che deliberatamente lo modifica cancellando la provenienza da un sito malevolo.
Normalmente questo header e presente nella maggior parte delle richieste HTTP e preservato anche nei reindirizzamenti HTTP, tranne nelle situazioni seguenti.
- Quando si digita manualmente un nuovo URL nella barra degli indirizzi o si apre una pagina dai preferiti o segnalibri.
- Quando la navigazione parte da un documento con un pseudo URL come data: o javascript:
- Quando la richiesta è il risultato di un reindirizzamento controllato dall’header Refresh (ma non nel caso in cui si usi l’header Location).
- Ogni volta che il sito di provenienza e crittografato e la destinazione è in chiaro. In base alla sezione 15.1.2 dell’RFC 2616, questo avviene per motivi di privacy, in realtà non ha molto senso. La stringa Referer viene trasmessa a terzi quando si da un sito crittografato a un altro e,a parità di altre condizioni,l’uso della crittografia non è sinonimo di attendibilità.
- Se l’utente decide di bloccare o modificare arbitrariamente questo header agendo sulle impostazioni del browser o installando un plug-in per la privacy.
Come dovrebbe risultarvi evidente, quattro di queste cinque condizioni possono essere riprodotte di proposito da qualsiasi sito.
Tipi di richieste HTTP
La prima specifica HTTP/0.9 definiva un unico metodo (o “verb”) per richiedere un documento: GET. Le successive versioni sperimentarono un sempre più strano insieme di metodi che consentissero interazioni diverse dallo scaricamento di un documento dall’esecuzione di uno script, tra cui curiosità come SHOWMETHOD, CHECKOUT e – perche no – SPACEJUMP.
La maggior parte di questi esperimenti di pensiero è stata abbandonata in HTTP che definisce un insieme molto piu gestibile di otto metodi. Solo i primi due, GET e POST, hanno qualche significato per il Web di oggi.
GET
I metodo GET è nato con il significato di “scaricamento di informazioni”. In pratica è utilizzato in quasi tutte le interazioni tra client e server nel corso di una normale sessione di navigazione. Le richieste GET tradizionali non trasportano alcun dato fornito dal browser, anche se la cosa non è vietata da alcuna specifica. Questo perché le richieste GET non dovrebbero avere, per citare l’RFC,“il significato di intraprendere un’azione diversa dallo scaricamento”, ovvero non dovrebbero operare modifiche persistenti allo stato di un’applicazione. Questa interpretazione ha progressivamente perso di significato nelle applicazioni moderne, dove lo stato spesso non viene nemmeno gestito sul lato server; conseguentemente questa raccomandazione e stata ampiamente ignorata dagli sviluppatori di applicazioni (si racconta – e forse c’è un fondo di verità – di uno sfortunato webmaster di nome john Breckman, il cui sito sarebbe stato accidentalmente cancellato da un robot di un motore di ricerca. II robot ha semplicemente scoperto un’interfaccia amministrativa non autenticata basata su GET, che John aveva scritto per il proprio sito… e ha allegramente seguito ogni collegamento “delete” che ha trovato).
POST
I metodo POST nasce per l’invio di informazioni (per lo più da moduli HTML) al server per la loro elaborazione. Dato che le azioni POST possono avere effetti persistenti sullo stato del server, molti browser chiedono conferma prima di ricaricare del contenuto scaricato con POST. Nella maggioranza dei casi, tuttavia GET e POST vengono utilizzati in maniera quasi intercambiabile.
Le richieste POST vengono spesso accompagnate da dei dati, la lunghezza dei quali è indicata dall’header Content-Length. Nel caso del codice HTML puro, tali dati possono consistere di stringhe con codifiche URL o MIME (un formato che vedremo in dettaglio nel Capitolo 4) anche se, di nuovo, la sintassi non è imposta in alcun modo a livello HTTP.
HEAD
HEAD e un metodo utilizzato di rado. È essenzialmente identico a GET, ma scarica solo gli header HTTP, senza i dati del documento vero e proprio. I browser in genere non effettuano richieste HEAD, ma il metodo viene a volte impiegato dai robot dei motori di ricerca e da altri strumenti automatici, per esempio per rilevare l’esistenza di un file o per controllarne la data di ultima modifica.
OPTIONS
OPTIONS e una metarichiesta che scarica l’insieme dei metodi supportati per un particolare URL (o *, che indica il server in generale) in un header di risposta. II metodo OPTIONS non viene impiegato praticamente mai nella pratica, salvo che nell’identificazione dei server; trattandosi di informazioni dal valore limitato, possono anche non essere molto accurate.
PUT
Una richiesta PUT consente l’invio di file su un server nella posizione esatta specificata dall’URL. Dato che i browser non supportano questo metodo, le funzioni di upload dei file sono quasi sempre implementate tramite POST a script lato server, piuttosto che con questo approccio – teoricamente molto più elegante.
Detto questo, alcuni client e server HTTP non web possono utilizzare questo metodo per i loro scopi. Alcuni server web possono essere configuarati (male) per accettare indiscriminatamente richieste PUT, creando un ovvio rischio per la sicurezza.
DELETE
DELETE è un metodo autoesplicativo (“cancella”) complementare a PUT – è analogamente poco utilizzato nella pratica.
TRACE
TRACE è una sorta di richiesta “ping” che restituisce informazioni su tutti i proxy attraversati nell’elaborazione di una richiesta. Riporta anche l’eco della richiesta origina browser non fanno richieste TRACE. Tali richieste vengono utilizzate molto di rado per scopi legittimi, il primo dei quali è la verifica della sicurezza: possono rivelare interessanti dettagli sull’architettura interna dei server HTTP di una rete remota. Proprio per questa ragione, questo sistema viene quasi sempre disabilitato dagli amministratori dei server.
CONNECT
II metodo CONNECT e concepito per stabilire connessioni non HTTP attraverso proxy HTTP. Non dev’essere inviato direttamente ai server. Se su un server viene abilitato accidentalmente il supporto al metodo CONNECT, si può avere un rischio per la sicurezza – offrire all’aggressore un modo di veicolare traffico TCP attraverso una rete altrimenti protetta.
Altri metodi HTTP
Un certo numero di altri metodi di richiesta sono poi stati sviluppati per essere impiagati da altre applicazioni o dalle estensioni dei browser; l’insieme più diffuso di tali estensioni HTTP è WebDAV, un protocollo di sviluppo e gestione delle versioni, descritto nell’RFC 4918.
Inoltre, anche l’API XMLHttpRequest consente a script JavaScript lato client di effettuare richieste con praticamente qualsiasi metodo verso il server di origine – anche se quest’ ultima possibilità è fortemente ristretta in alcuni browser.
Codici di risposta del server
La Sezione 10 dell’RFC 2616 elenca quasi 50 codici di stato che un server può utilizzare per costruire una risposta. Circa 15 di questi vengono utilizzati nella vita reale, i rimanenti sono li per indicare stati via via più bizzarri o improbabili come “402 Paymc Required” o “415 Unsupported Media Type”. La maggior parte degli stati di questo elenco non corrisponde con esattezza al comportamento delle moderne applicazioni web; la sola ragione della loro esistenza è che qualcuno ha sperato che un giorno lo avrebbe rispecchiato.
Alcuni codici meritano comunque di essere memorizzati, perché molto comuni o con significati particolari, come vediamo nel seguito.
200-299: successo
Questo intervallo di codici di stato indica il completamento di una richiesta con successo:
200 OK. E la risposta normale a una richiesta GET o POST che va a buon fine. II browser visualizza i dati ricevuti immediatamente dopo o li processa in qualche altro modo, dipendente dal contesto.
204 No Content. Questo codice viene talvolta utilizzato per indicare una richiesta a buon fine – quando non ci si aspetta nessun dato come risposta. II codice 204 interrompe la navigazione sull’URL che l’ha generato e mantiene l’utente sulla pagina di origine.
206 Partial Content. È analogo al codice 200. Viene prodotto dal server in risposta a richieste di blocchi da parte del browser. II browser deve già essere in possesso delle altre parti del documento (o non ne avrebbe richiesto solo un blocco) ed esaminerà l’header di risposta Content-Range per ricomporlo prima di effetturarne l’elaborazione.
300-399: reindirizzamento e altri messaggi di stato
Questi codici vengono utilizzati per comunicare una varietà di stati che non indicano un errore, ma che richiedono un trattamento particolare da parte del browser:
301 Moved Permanently, 302 Found, 303 See Other. Queste risposte indicano al browser di ripetere la richiesta a un nuovo server, specificato nell’header di risposta Location. Nonostante le distinzioni che vengono fatte nell’RFC, tutti i browser moderni quando incontrano questi codici di risposta rimpiazzano POST con GET, eliminano il payload e reinoltrano la richiesta automaticamente.
304 Not Modified. Questa risposta indiretta informa il client che il documento richiesto non e stato modificato rispetto alla copia già in suo possesso. È la risposta a una richiesta condizionata con header come If-Modified-Since, che viene inviata per convalidare nuovamente la cache di documenti del browser. II corpo della risposta non viene visualizzato all’utente. Se il server risponde in questo modo a una richiesta non condizionata, il risultato dipende dal browser e puo essere ridicolo; per esempio, Opera apre una richiesta di download che poi non funziona.
307 Temporary Redirect. Analogamente al codice 302, ma a differenza degli altri metodi di reindirizzamento, i browser non trasformano la richiesta da POST a GET per eseguire un reindirizzamento 307. Questo codice non si usa spesso nelle applicazioni web, e alcuni browser non si comportano coerentemente quando lo ricevono.
400-499: errori lato client
Questo intervallo di valori viene utilizzato per indicare condizioni di errore provocati dal comportamento del client:
400 Bad Request (e messaggi correlati). II server non è in grado o non vuole processare la richiesta per qualche motivo non specificato. II payload della rispostà in genere spiega il problema e generalmente viene gestito dal browser come una risposta 200. Esistono anche varianti più specifiche, come “411 Length Required” “405 Method Not Allowed” o “414 Request-URI Too Long”. Ci chiediamo tutti perché l’assenza dell’header Content-Length meriti un codice di risposta dedicate (411), mentre l’assenza dell’header Host debba accontentarsi solo di un codice 400 generico.
401 Unauthorized. Questa risposta indica che l’utente deve fornire delle credenziali di autenticazione a livello di protocollo HTTP per accedere alla risorsa. In genere a questo punto il browser chiede all’utente le informazioni per fare il login e visualizza il corpo della risposta solo se il processo di autenticazione non va a buon fine. Questo meccanismo viene illustrato in maggior dettaglio più avanti nel paragrafo dedicato all’autenticazione HTTP.
403 Forbidden. L’URL richiesto esiste ma non può essere scaricato per ragioni diverse dall’autenticazione HTTP, per esempio permessi di accesso al filesystem non sufficienti, una regola di configurazione sul server che vieta l’accesso alla risorsa, credenziali insufficienti di qualche tipo – come cookie non validi o un indirizzo IP di origine non valido. Questa risposta viene generalmente visualizzata all’utente.
404 Not Found. L’URL richiesto non esiste. Questa risposta viene generalmente mostrata all’utente.
500-599: errore lato server
È una classe di messaggi di errore, prodotti come risposta a problemi verificatisi sul server:
500 Internal Server Error, 503 Service Unavailable, e cosi via. II server ha un problema che determina l’impossibilita di onorare la richiesta. Può trattarsi di un problema temporaneo, il risultato di una configurazione errata o semplicemente l’effetto di una richiesta a una locazione inattesa. Questa risposta viene generalmente mostrata all’utente.
Semantica dei cookie HTTP
I cookie HTTP non fanno parte dell’RFC 2616, ma sono una delle principali estensioni del protocollo utilizzate sul Web. II meccanismo dei cookie consente ai server di memorizzare minuscole coppie nome=valore in modo trasparente nel browser, inviando l’header di risposta Set-Cookie e ricevendole indietro nelle future richieste tramite il parametro client Cookie.
I cookie sono decisamente il modo piu usato di mantenere le sessioni aperte e autenticare le richieste degli utenti; sono una delle quattro forme canoniche di ambient authority sul Web; le altre sono l’autenticazione integrata HTTP, la verifica degli IP e i certificati dei client. L’ambient authority e una forma di controllo d’accesso basata su una proprieta globale e persistente dell’entita richiedente, invece che su una forma esplicita di autorizzazione che sarebbe valida solo per un’azione specifica.
Un cookie che identifichi un utente, che venga incluso indiscrimitatamente in ogni richiesta in uscita verso un dato server, senza alcuna considerazione sul perche venga fatta tale richiesta, ricade in questa categoria.
Implementato in origine da Lou Montulli in Netscape intorno al 1994, e descritto in un breve documento informale di quattro pagine15, questo meccanismo non e stato inserito in alcuno standard nei successivi 17 anni. Nel 1997 l’RFC 210916 ha cercato di documentare questo status quo ma, inspiegabilmente, ha proposto un certo numero di modifiche che, a oggi, la renderebbero sostanzialmente incompatibile con l’attuale comportamento dei browser moderni. Un altro ambizioso sforzo – Cookie2 – venne alia luce nell’RFC 296517 ma un decennio piu tardi continua a non avere il supporto di alcun browser, situazione che ha ben poche probability di cambiamento. Un nuovo sforzo per scrivere una specifica ragionevolmente accurata sul meccanismo dei cookie – RFC 626518 – si e concluso appena prima della pubblicazione di questo libro, ponendo finalmente termine a questa mancanza di certezze.
A causa della prolungata assenza di standard reali, le implementazioni si sono evolute in modi molto interessanti e talvolta incompatibili. In pratica, si possono creare dei nuovi cookie utilizzando l’header Set-Cookie seguito da un’unica coppia nome=valore e da un certo numero di parametri opzionali separati da punto e virgola che ne defmiscono campo d’applicazione e validita.
Expires. Specifica la data di scadenza di un cookie in un formato simile a quello usato per gli header Date ed Expires. Se un cookie viene creato senza un’esplicita data di scadenza, viene generalmente tenuto in memoria per la durata della sessione del browser (che, specialmente sui computer portatili con la funzione di sospensione, puo anche significare settimane). I cookie con scadenza regolare, invece, vengono salvati su disco e soprawivono tra le varie sessioni, a meno che le impostazioni sulla privacy dell’utente non ne impongano la cancellazione.
Max-age. Questo metodo alternativo di impostare una data di scadenza – suggerito dai documenti RFC – non e supportato da Internet Explorer e percio non viene utilizzato nella pratica.
Domain. Questo parametro permette al cookie di essere utilizzato in un dominio piu vasto del nome di host restituito dall’header Set-Cookie. Le regole precise di questo meccanismo e le relative conseguenze sulla sicurezza sono trattate nel Capitolo 9.
Path. Consente a un cookie di avere validita a partire da un particolare percorso. Non e u n meccanismo di sicurezza attuabile nella pratica per le ragioni che vedremo nel Capitolo 9. Puo essere utilizzato per comodita, per evitare che dei cookie con nomi identici possano essere utilizzati in diverse parti di una stessa applicazione.
Secure. Vieta che il cookie venga trasmesso su connessioni non crittografate.
HttpOnly. Fa si che il cookie non possa essere letto attraverso l’API document.cookie di JavaScript. E un’estensione di Microsoft che pero oggi e supportata da tutti i maggiori browser.
Nell’effettuare le successive richieste a un doniinio per cui hanno dei cookie validi, i browser combinano tutte le coppie nome-valore in un unico header Cookie separato da punti e virgola, senza alcun metadato aggiuntivo, che spediscono al server. Se ci sono troppi cookie da inviare in una particolare richiesta, vengono superati i limiti dimensionali per gli header sul server e la richiesta fallisce; non c’e alcun modo per risolvere questa condizione, se non quella di ripulire manualmente l’archivio dei cookie.
Curiosamente, non esiste alcun metodo esplicito con cui i server HTTP possano richiedere la cancellazione dei cookie non piu necessari. Tuttavia, ciascun cookie e iilentificato univocamente da una tupla nome-dominio-percorso (gli attributi secure e httponly vengono ignorati), e questo permette a un vecchio cookie con lo stesso campo ill applicazione di essere semplicemente sovrascritto. Inoltre, se il cookie che sovrascrive ha una data di scadenza gia trascorsa (la data di expires e collocata nel passato), verra immediatamente azzerato: un modo bizantino di cancellare dei dati.
Anche se l’RFC 2109 richiede che debbano essere accettati diversi valori separad da virgola in un unico header Set-Cookie, questa pratica e pericolosa e non piu supportata d.ii browser. Firefox permette di impostare piu cookie per volta tramite 1’API Javascript document.cookie ma, inspiegabilmente, richiede degli avanzamenti riga come delimita- lori al posto delle virgole.
Nessun browser usa le virgole come delimitatori dei Cookie, c riconoscerle lato server andrebbe considerato poco sicuro.
Un’altra importante differenza tra la specifica e la realtà consiste nel fatto che i valori nei cookie dovrebbero utilizzare il formato quoted-string delle specifiche HTTP (cfr. il precedente paragrafo dedicato agli header delimitati da punto e virgola), ma solo Firefox e Opera riconoscono tale sintassi nella pratica. Affidarsi a valori quoted-string e quindi insicuro, cosi come permettere virgolette spurie all’interno di cookie controllati da malintenzionati”.
I cookie non garantiscono di essere particolarmente affidabili. I programmi lato utente permettono di influire ben poco sul numero e la dimensione dei cookie permessi per ciascun dominio e, come caratteristica male interpretata di privacy, possono limitarnc la ilurata di vita. Dato che si puo ottenere la tracciatura dell’utente con affidabilita equi- valente in altri modi, gli sforzi di applicare la tracciatura basata sui cookie producono piu danno che benefici.
Crittografia a livello di protocollo e certificati client
Come dovrebbe risultare ormai evidente, tutte le informazioni delle sessioni HTTP vengono scambiate come testo in chiaro nella rete. Negli anni Novanta questo non sarebbe stato un gran problema: certo il testo in chiaro esponeva i propri gusti di navigazione alla vista del provider di Internet impiccioni, o forse ad altri utenti maliziosi del proprio ufficio, o a qualche zelante agenzia governativa, ma la cosa non sembrava peggiore del comportamento di SMTP, DNS e di tutti gli altri protocolli di uso comune. Purtroppo la crescita di popolarità del Web come piattaforma di commercio elettronico ha aggravato il rischio, e la sostanziale regressione della sicurezza di rete causata dalla diffusione di reti Wireless pubbliche è stata la goccia che ha fatto traboccare il vaso.
Dopo alcune pezze di scarso successo, una vera soluzione a questo problema fu proposta nell’KFC 2818: perché non incapsulare normali richieste HTTP all’interno di un esistente, multifiinzionale meccanismo di sicurezza noto come TLS o SSL (Transport Lyer Security) sviluppato diversi anni prima? Questo sistema di trasporto fa uno di crittogra a chiave pubblica per creare un canale di comunicazione confidenziale e autenticato tra due punti di rete, senza richiedere alcun tipo di modifica al protocollo HTTP.
La crittografia a chiave pubblica si basa su algoritmi di crittografia asimmetrici. Viene creata una coppia di chiavi: una privata, mantenuta segreta dal proprietario e necessaria per decifrare i messaggi, e una pubblica, che viene diffusa al mondo e utile solo per cifrare i messaggi destinati al proprietario (ma non per decifrarli).
Per consentire ai server web di provare la propria identità, ogni browser compatibile con HTTPS viene fornito con un piccolo corredo di chiavi pubbliche appartenenti a alcune autorita di certificazione (CA, Certificate Authorities). Le CA sono organizzazioni ritenute affidabili dai fornitori di browser, che attestano che una particolare chiave pubblica appartiene a uno specifico sito – dopo aver controllato l’identità della persona che chiede tale attestazione e averne verificato la titolarità del dominio in questione.
L’insieme delle organizzazioni di fiducia è vario, arbitrario e non particolarmente ben documentato, cosa che spesso solleva motivate critiche. Nonostante tutto, alla fine il sistema fa il proprio lavoro ragionevolmente bene. Solo alcuni svarioni sono stati documentati a oggi (compresa la recente compromissione di un’azienda di alto profilo di nome Comodo), e non ci sono notizie di abusi dei privilegi di CA. Nell’implementazione attuale, quando si stabilisce una nuova connessione HTTPS il browser può riceve una chiave pubblica firmata dal server; ne verifica la firma (che non può essere applicata se non si ha accesso alla chiave privata della CA), poi controlla che i campi cn (common name) o subjectAltName del certificato indichino che è stato rilasciato per il server con cui si vuole dialogare e si accerta che la chiave non sia inserita in un elenco pubblico di chiavi revocate (per esempio perche compromessa o ottenuta con metodi illegali). Se l’esito di tutte queste verifiche è positivo, il browser può procedere a crittografare i messaggi diretti al server con la chiave pubblica che ha ricevuto ed essere certo che solo il server potrà decifrarli.
Normalmente il client rimane anonimo: genera una chiave crittografica temporanea, ma il processo non prova l’identita del client. Una prova di questo tipo puo essere necessaria, pero. In alcune organizzazioni si e iniziato a utilizzare i certificati per i client e in molte nazioni sono stati adottati addirittura a livello statale (per esempio per meccanismi di e-government). Dato che lo scopo principale dei certificati client e quello di fornire informazioni sull’identita reale dell’utente,in genere i browser chiedono conferma prima di inviarli a siti non conosciuti, per ragioni di privacy; oltre a questo, il certificato può fungere come una ulteriore forma di ambient authority.
Vale la pena di notare che, sebbene HTTPS in quanto tale sia uno schema in grado di resistere ad attacchi sia attivi che passivi, non fa molto per nascondere l’evidenza di un accesso a informazioni pubbliche. Non maschera la richiesta HTTP grezza e le dimensioni delle risposte, la direzione del traffico e le tempistiche di una tipica sessione di navigazione. La cosa da la possibility a un aggressore passivo e con pochissima padronanza tecnica di venire a conoscenza, per esempio, di quale imbarazzante pagina di Wikipedia la vittima stia visualizzando su un canale cifrato. Infatti, in un caso estremo, alcuni ricercatori Microsoft hanno illustrato l’uso di sistemi di profilazione dei pacchetti e hanno ricostruito la sequenza di tasti digitati dall’utente durante 1’uso di un’applicazione online.
Regole di gestione degli errori
In un mondo ideale, un sospetto di errore in un certificato SSL, come un nome di host scritto in modo fuorviante o un’autorità di certificazione non riconosciuta, causerebbe l’impossibilità di stabilire una connessione. Errori meno sospetti, come certificati scaduti da pochi giorni o un nome di host errato, potrebbero essere accompagnati da semplici avvisi.
Sfortunatamente la maggioranza dei browser ha indiscriminatamente scaricato la responsabilità del problema sull’utente, cercando di spiegare la crittografia in termini da profani (fallendo clamorosamente) e richiedendo che fosse quest’ultimo a prendere la decisione: vuoi veramente vedere questa pagina o no? La Figura 3.1 mostra una finestra di dialogo di questo tipo.
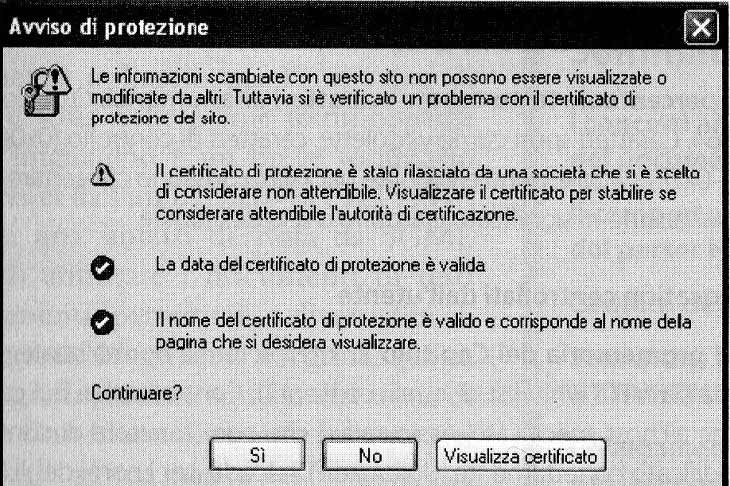
Il testo e l’aspetto degli avvisi SSL si è evoluto negli anni verso spiegazioni incredibilmente stupide (ma sempre problematiche) del problema e azioni sempre più complicate necessarie per superare gli avvisi. Questa tendenza non ha sortito gli effetti sperati: alcune ricerche mostrano che più del 50% degli avvisi più terrorizzanti viene scavalcato dagli utenti. È facile dare la colpa agli utenti, ma – alla fine – si fanno loro le domande sbagliate e si offrono loro esattamente le scelte sbagliate. In tutta franchezza, se è opinione comune che saltare gli avvertimenti sia vantaggioso in alcuni casi – offrire di aprire la pagina in una modalità chiaramente etichettata come “sandbox” dove i danni risulterebbero limitati sarebbe una soluzione decisamente più azzeccata. Quando invece tale convinzione non c’è, si dovrebbe eliminare ogni possibilità di superare il blocco (obiettivo della Strict Transport Security, meccanismo sperimentale che vedremo nel Capitolo 16).